Gain data clarity with fuzzy matching in Snowflake
The problem
When your tables are well modeled and maintained, joining datasets can be a very straightforward process. Grab your primary key from table A, your foreign key from table B, and you’re off to the races.
However, we often run across situations where there are no happy relationships like this and we have to resort to “fuzzy matching”. Essentially, fuzzy matching employs different comparison methods and algorithms to determine how similar two string values are. The scores returned by these algorithms, and the threshold you establish for acceptance enable you to programmatically match strings that are not exact matches.
Describing how these various algorithms work is beyond this article. Though there are plenty of libraries available in Python, R, and Spark to help implement them, architecting a production solution can get complicated very fast. Thankfully, Snowflake has implemented several of these algorithms as standard SQL functions- making them a valuable component in broader data platform modernization efforts.
The datasets
Imagine you are a streaming service provider with multiple platforms. You capture various viewership data which is then analyzed to gain insights into not just the assets themselves, but the platforms they’re on, the time of day they’re streamed, how long viewers watch, etc. Unfortunately, none of the platforms report data in the same way, and data format issues are the least of your concerns. The primary issue is each platform has its own unique identifier for each show.
Solving these challenges—such as harmonizing identifiers through fuzzy matching—is a critical step in data platform modernization, ensuring that analytics teams can work with unified, high-quality datasets to drive better business decisions.
How can you join the datasets?
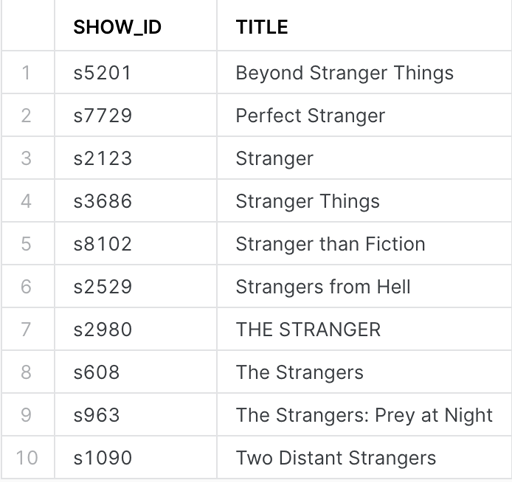
The Netflix Movies and TV Shows dataset from Kaggle is a listing of about 8,800 movies and TV shows on Netflix. Among the fields are a SHOW_ID and a TITLE, and they both hold unique values.
It would be nice if every platform reported viewership data with the SHOW_ID. If not that, the TITLE would be fine – as long as every platform used the exact same title. Unfortunately, our platform data looks something like this:
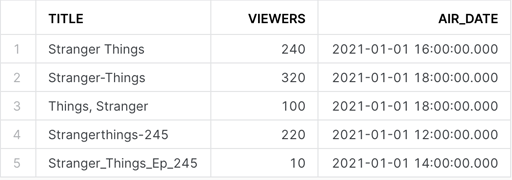
If we were to join our two datasets on TITLE, the only matching data would be the first record and we’d lose everything else.
We could try some of Snowflake’s other very useful comparison functions such as CONTAINS, LIKE(all, any) /, ILIKE(any), or SUBSTR. We might even get fancy with Regular Expressions. More than likely though, these solutions won’t get us to where we want to be.
Fuzzy functions
Two of the more effective and popular string metrics have been codified as standard functions in Snowflake:
EDITDISTANCE is a codification of the Levenshtein distance algorithm. Given two strings, the Levenshtein algorithm counts how many single-character insertions, deletions, or substitutions would be needed to convert one string to another; the lower the number, the closer the two strings. For example, editdistance(‘red’, ‘reidd’) would return 2 – drop the ‘i’ and the ‘d’ from ‘reidd’ and you have ‘red’.
JAROWINKLER_SIMILARITY is similar, but only considers matching characters and any transpositions (swapping of letters) required to turn one string into another. It also gives priority to prefixes, so strings that start with the same characters will receive a higher score. Additionally, Jaro-Winkler returns a normalized value between 0 and 100 where 0 is no match and 100 is a perfect match. So, jarowinkler(‘red’, ‘reidd’) would return 89 – a pretty good match.
The final Snowflake function for fuzzy comparisons is SOUNDEX. Given a single string, SOUNDEX will return a string which is the phonetic representation in English of that string. This is good for strings which typically get misspelled and might be implemented in your join clause as ON SOUNDEX(MASTER.TITLE) = SOUNDEX(LOG.TITLE).
Putting it all together
We’ll be using the EDITDISTANCE function in this example, but it’s best practice to standardize the title strings on both sides regardless of which method you go with:
- Convert everything to lower string
- Remove all non-alphanumeric characters
- Remove all white space
A simple user-defined function could be created to handle this:
create or replace function standardize(a string)
returns string
comment = 'Removes non-alphanumeric characters and casts the result to lower case'
as $$select regexp_replace(lower(trim(a)),'[^a-z0-9]', '')$$
;Add new fields to both your asset table and your platform data to hold these standardized titles so we can join on them.
We’ll also want to normalize the EDITDISTANCE results so they’re easily comparable. Again, a simple user-defined function can be employed here to divide the score by the longest string and subtract the result from 1:
create or replace function ed_dist_score(a string, b string)
returns number
comment = 'Normalizes the editdistance score for two strings'
as 'select 1.0-(editdistance(a, b)/greatest(length(a),length(b)))'
;This gives us a value between 0 and 1 when we compare strings.
Now we’re ready to attempt our matching. Fuzzy matching is computationally expensive because each record in our log/platform dataset needs to be compared to every record in the master dataset. The result set is going to be the product of both datasets. So, if your master dataset is 1000 records, and your log/platform dataset is 10,000 records, your resultset is going to be 1000 X 10,000 = 10,000,000 records, and those are pretty conservative numbers!
Even though Snowflake is more than capable of handling anything you throw at it, one way of reducing the number of pairs is to use blocking – essentially segregating the data based on some shared quality. For example, since our master dataset distinguishes between movies and TV shows, if our log/platform data does as well, we might add a where clause to compare movies to movies and TV shows to TV shows.
select
log.title as log_title
, mstr.title as mstr_title
, util_db.public.ed_dist_score(mstr.standardized, log.standardized) as score
from
das42_shows mstr
cross join log_file log
where
mstr.type = log.type
order by 1,2,3
;Here’s a relevant selection of records from our query:
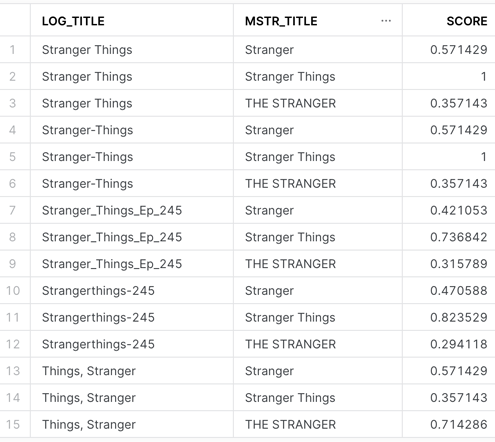
If we set a threshold score of .7, we’ll get accurate matches to most of the log/platform records, but we’ll also get a false positive – “Things, Stranger” is mapped to “THE STRANGER”:
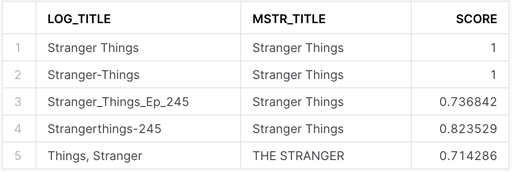
If we set a threshold score of .8, we’ll eliminate the false positive, but we’ll also lose “Stranger_Things_Ep_245”. This is where the art comes in. You don’t want to overfit, and you don’t want to underfit. Experimentation will help you find the sweet spot.
Further improvements
There are several more steps you can take to improve your results.
In the standardization process, you could consider removing stop words and/or articles since they’re rarely essential to the base subject. Creating word stems and adding them to a dictionary of sorts could likewise improve the pool of possible matches.
We used the Levenshtein distance for our score, but your dataset may have better luck with Jaro-Winkler, or SOUNDEX. You should test them all to see which yields the best results, or you could use a combination of methods, commonly known as Ensemble Modeling.
A technique we often utilize is to create a table of known variations in the log/platform data and map those values to the standardized values in our master dataset. This table sits between our log/platform data and the master dataset – a sort of pre-mapping that allows us to set a high threshold score. Any titles which fall below the threshold score are output to a table which is reviewed by a data steward familiar with the data. After the data steward makes the match, the new log/platform title, along with the standardized value it should match to, is added to the mapping table. Any subsequent occurrences of values which previously did not meet the threshold score will now match exactly creating a sort of virtuous cycle.
Conclusion
As you can see, there’s a lot we didn’t cover here – probably more than we actually did cover. However, the goal was to introduce you to the built-in matching functions in Snowflake with practical application. These are very powerful algorithms which would involve a great deal of programming in any language – even with available libraries. Snowflake makes their implementation exceedingly simple.
Contact us to explore how DAS42 can help resolve your complex problems with simple and innovative solutions. We are a Snowflake Elite Services Partner and winner of the 2022 Americas Innovation Partner of the Year award, and have helped all of our clients ensure they’re maximizing their tech stack with elegant, and effective solutions.

Services provided