There is a lot of buzz around the Snowpark Python SDK, which provides a Snowflake-native framework for developers to work with their data using Python. One primary advantage of the Snowpark Python SDK is that developers can leverage Python’s benefits without data ever leaving Snowflake’s infrastructure—you bring your code to the data instead of bringing your data to the code.
The advantages to this architecture are plentiful, but security, scalability, and elasticity are the highlights. Additionally, Snowflake has partnered with Anaconda to provide out-of-the-box support for hundreds of popular libraries. Also, converting Snowflake DataFrames to everyone’s favorite Pandas DataFrames is as simple as a single line of code.
Under the hood, Snowflake converts Python operations to SQL and executes the commands on the same virtual warehouses developers know and love today. This means Snowpark for Python is not inherently more expensive than executing SQL commands. Still, it may lead you to ask, “If Snowflake eventually converts the operations back to SQL, what is the point?”
There are several valid answers to this question. But it boils down to some data problems being more of a ‘Python problem’ than a ‘SQL problem,’ and there are tangible advantages to using the right tool for the right job. One of my favorite development quotes comes to mind: “If all you know how to use is a hammer, then everything looks like a nail.”
A Real World Example
In this example, DAS42 works closely with a large managed services department in the telecom industry, where the primary responsibility is building a robust data platform to support the business. The managed services department focuses on SD-WAN architecture, implementation, and continuous support. Our client designs, installs, and maintains their customer’s network infrastructure—ensuring that devices stay online and connected to the world. Therefore, a significant part of the product offering is understanding the current health of customers’ networks. Hardware in the physical world is constantly streaming information about what it is doing. We want that streamed data, and we want it in Snowflake. But here’s the catch—some of the data is in unstructured—syslog format.
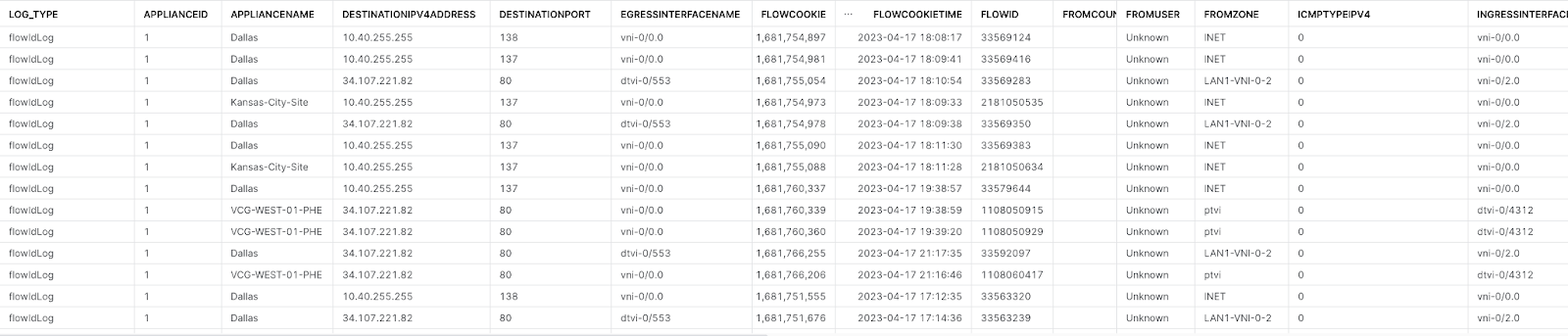
So we need to turn something that looks like this:
2023-04-17T16:33:25+0000 flowIdLog, applianceName=VCG-EAST-01-PHE, tenantName=Westeros, flowId=34762083, flowCookie=1681749523, sourceIPv4Address=172.16.102.102, destinationIPv4Address=8.8.8.8, sourcePort=64447, destinationPort=53, tenantId=9, vsnId=0, applianceId=1, ingressInterfaceName=dtvi-0/3766, egressInterfaceName=vni-0/0.0, fromCountry=, toCountry=, protocolIdentifier=17, fromZone=ptvi, fromUser=Unknown, toZone=RTI-INET-Zone, icmpTypeIPv4=0
Into a nice, clean, and columnar Snowflake table like this:
We could write SQL to perform this transformation, but it would be challenging to write, difficult to debug, and would perform inefficiently. Alternatively, we could leverage the Snowpark Python SDK to write a relatively simple string manipulation Python script to transform this unstructured data into semi-structured data and then let Snowflake’s outstanding semi-structured features take care of the rest. Python is the right tool for this initial transformation.
How the Solution Looks
You can define a Python UDF directly in Snowflake’s new Python worksheets, which allows you to write and test Python operations directly in the Snowflake UI. Once you approach this problem with Python instead of SQL, it ends up being pretty straightforward—just three functions, and two of them handle some source-specific data quality issues having to do with rogue commas:
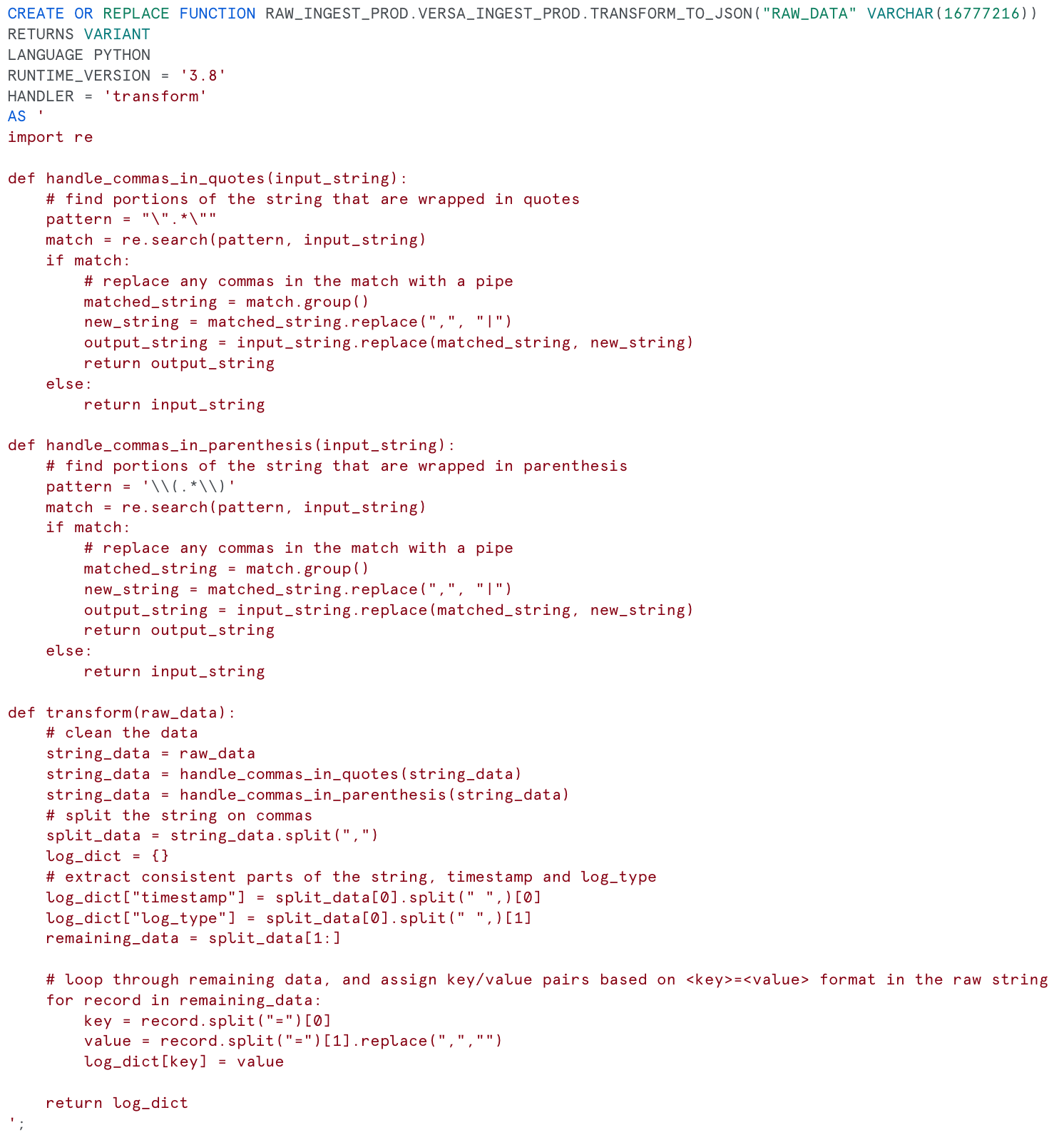
Because our Python transform is insulated in a Snowflake function, we can call that UDF in SQL workflows as part of the broader pipeline. What would have been some very awful SQL is simply:
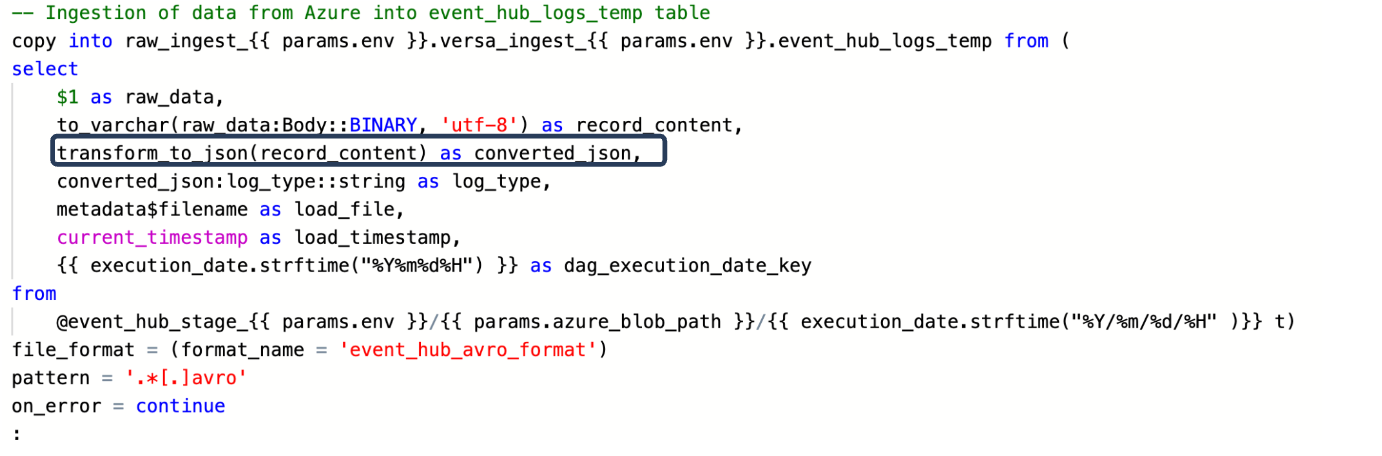
This is a ‘copy into’ statement, so we’re reading some data into Snowflake from cloud storage. Upstream of Snowflake, a managed Kafka streaming process, continuously lands the unstructured data in Avro format in a cloud storage bucket. We can wrap this ‘copy into’ statement up in a Snowpipe for real-time loading or orchestrate the command to execute on some cadence for batch loading. Regardless, the first column, raw_data, is the data as it appears in the cloud storage bucket in binary format. The second column, record_content, is raw_data converted to human-readable, so it is a string in an unstructured format. Then, in the third column, we call our previously defined Python UDF directly in SQL and hand it record_content as an input argument. The UDF spits out a variant column in JSON format. The result of the above copy into statement leaves us with a table like this:

Each column is a progression in the overall transformation. We start with unstructured data in binary. We use an out-of-the-box Snowflake function to convert that string into something human-readable. Finally, we pass that unstructured string into our Python UDF and get the data back in JSON format. Now, all that is left to do is convert that final output into the typical columnar storage we all know and love using Snowflake’s native semi-structured features:
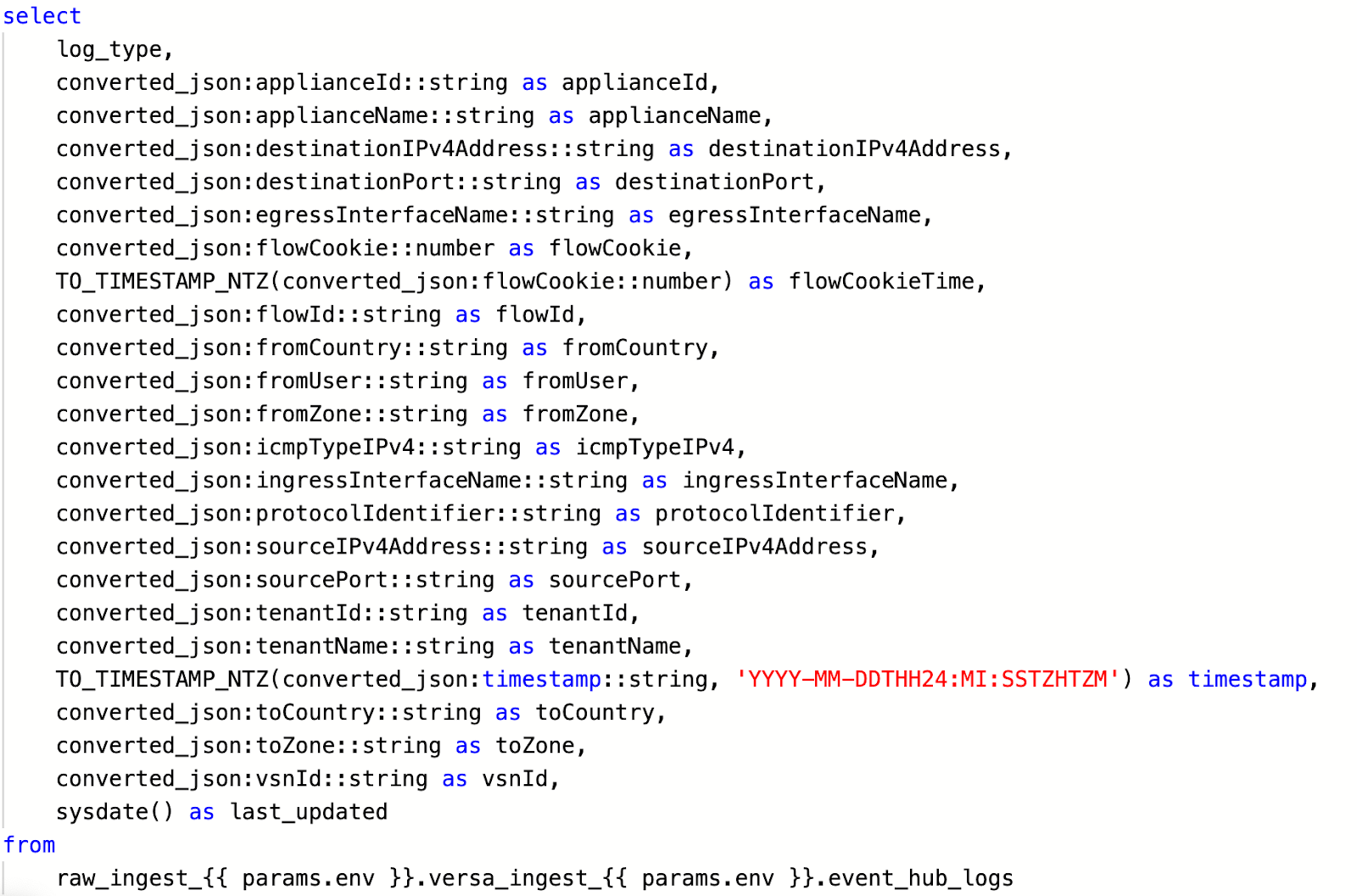
Which leaves us with our desired final output:
This is an example of a transformation that is more of a Python problem than a SQL problem—it was a lot easier for our team to complete the desired transformation using Python instead of SQL. Overall, this saves development time and yields code that is easier to read, write, and debug. Our data stayed on Snowflake, even though we interacted with the data using a different programming language than SQL. The other benefit here is we achieve simplicity and readability in our pipeline. An otherwise unique data source format looks and feels like the rest of our sources once the UDF transform is applied.
Conclusion
Now, fresh off the heels of several exciting announcements from Snowflake Summit 2023, where Snowflake announced even more features that play well with Python, Snowpark for Python will only increase in utility. With features like containerized apps, large language models and other ML capabilities, a Streamlit integration, and more, there is an exciting new world of Python-centric problems to solve in Snowflake—and Snowpark for Python will be right in the center of it all.
Contact us to explore how DAS42 can help resolve your complex problems with simple and innovative solutions. We are a Snowflake Elite Services Partner and winner of the 2022 Americas Innovation Partner of the Year award, and we have helped all of our clients ensure they’re maximizing their tech stack with elegant and effective solutions.

Services provided